Bind an evaluator to a dataset in the UI
While you can specify evaluators to grade the results of your experiments programmatically (see this guide for more information), you can also bind evaluators to a dataset in the UI. This allows you to configure automatic evaluators that grade your experiment results without having to write any code. Currently, only LLM-based evaluators are supported.
The process for configuring this is very similar to the process for configuring an online evaluator for traces.
When you configure an evaluator for a dataset, it will only affect the experiment runs that are created after the evaluator is configured. It will not affect the evaluation of experiment runs that were created before the evaluator was configured.
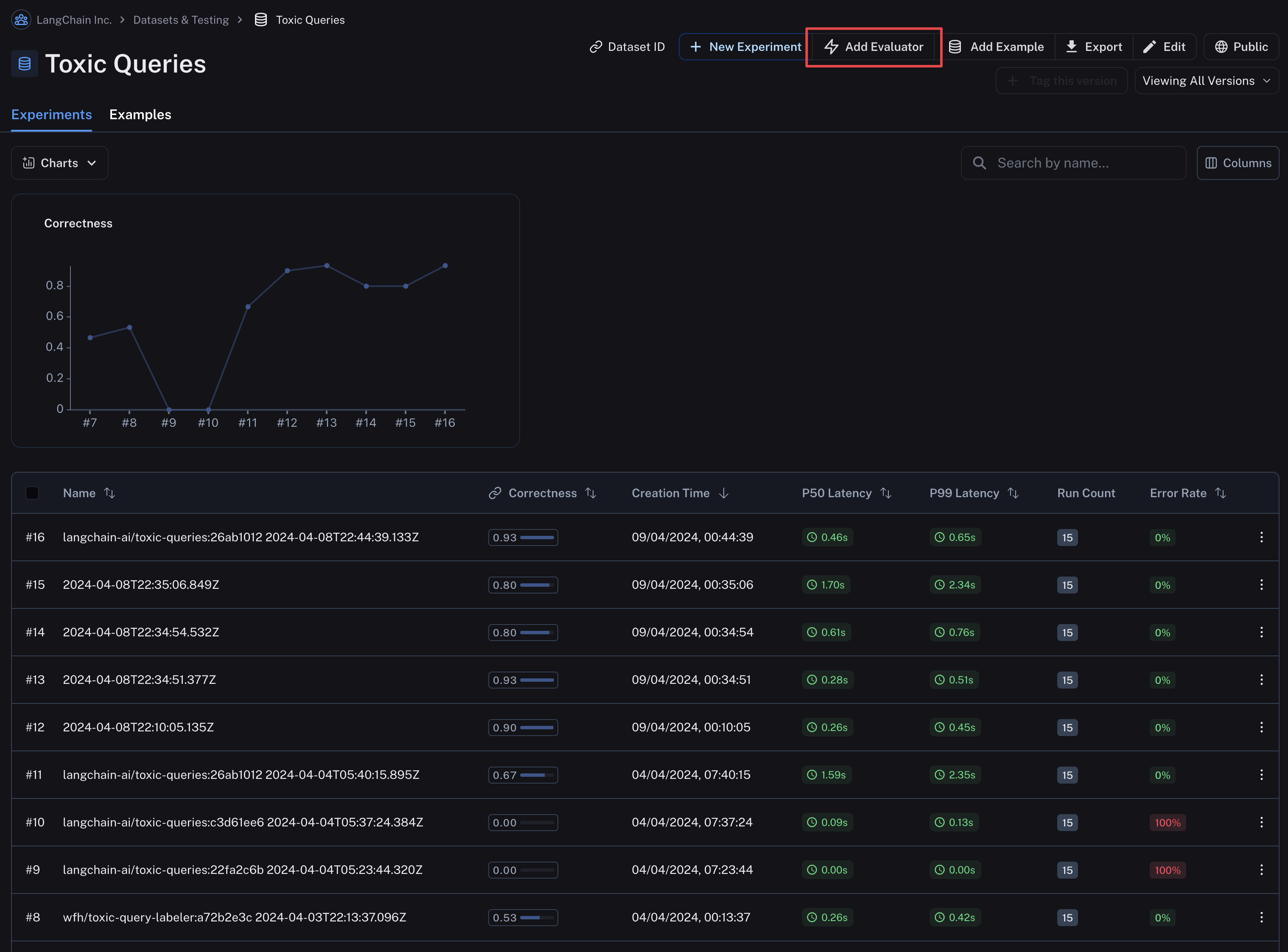
- Navigate to the dataset details page by clicking Datasets and Testing in the sidebar and selecting the dataset you want to configure the evaluator for.
- Click on the
Add Evaluatorbutton to add an evaluator to the dataset. This will open a modal you can use to configure the evaluator.
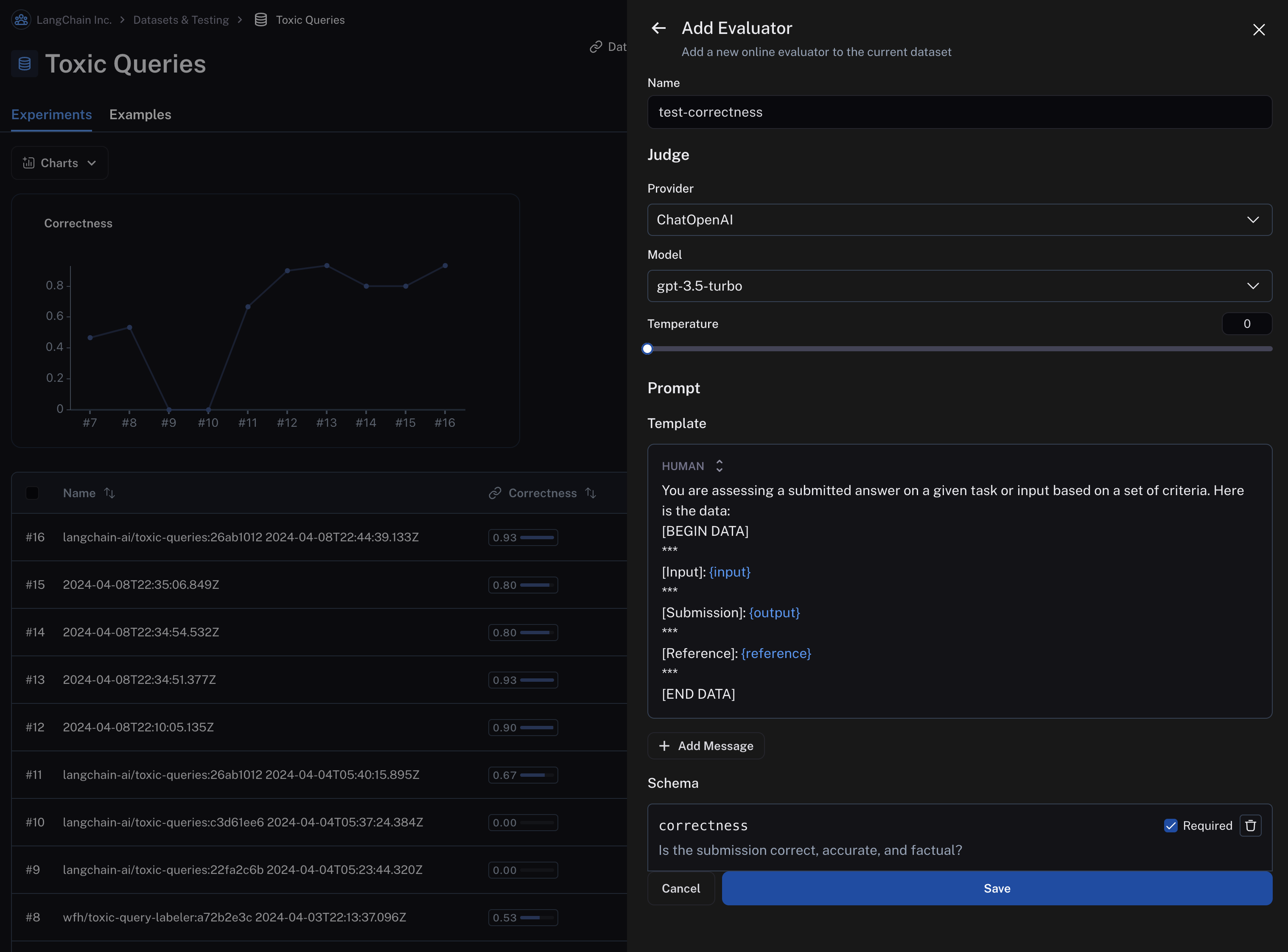
- Give your evaluator a name and set an inline prompt or load a prompt from the prompt hub that will be used to evaluate the results of the runs in the experiment.
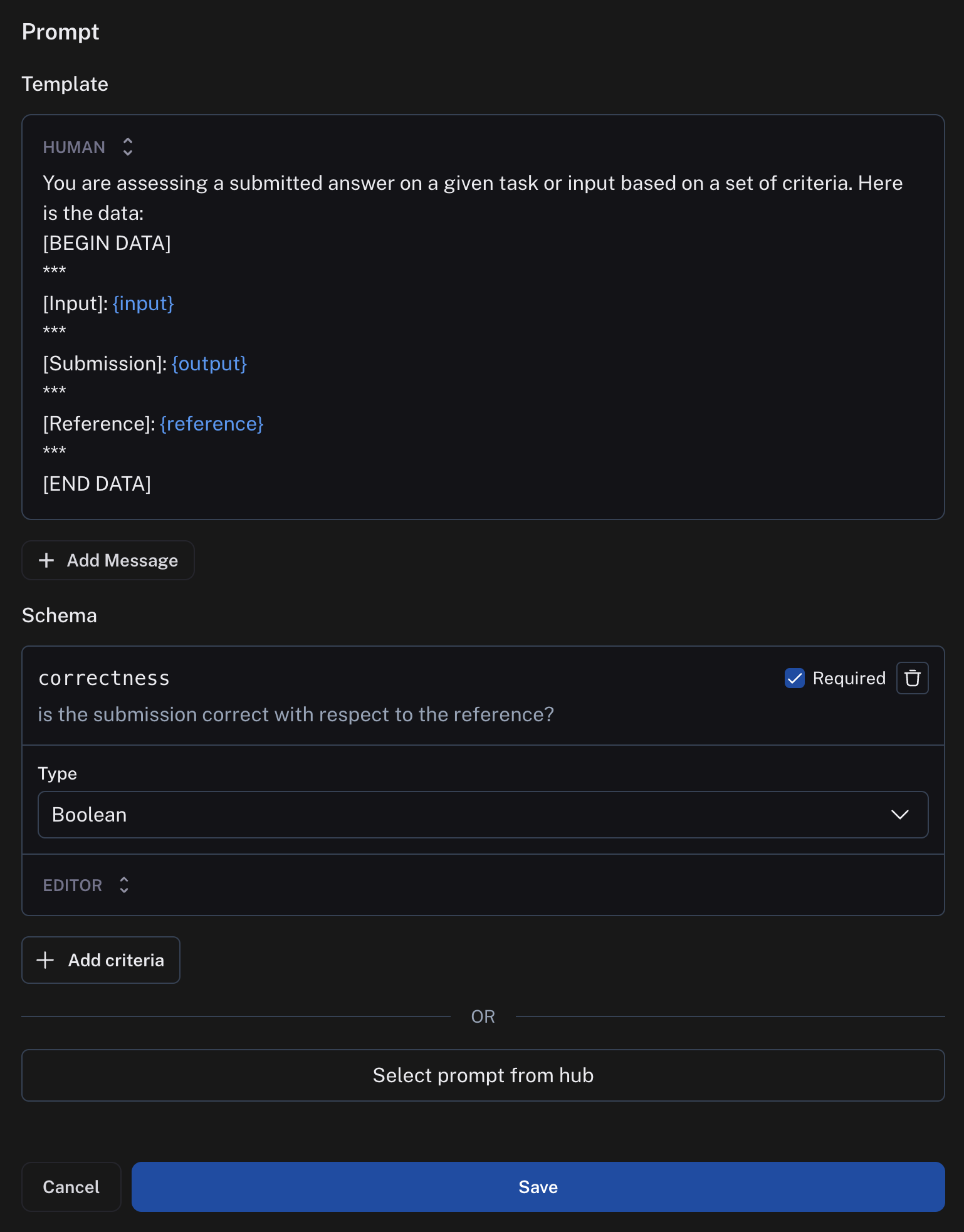
Importantly, evaluator prompts can only contain the following input variables:
input(required): the input to the target you are evaluatingoutput(required): the output of the target you are evaluatingreference: the reference output, taken from the dataset
Automatic evaluators you configure in the application will only work if the inputs to your evaluation target, outputs from your evaluation target, and examples in your dataset are all single-key dictionaries.
LangSmith will automatically extract the values from the dictionaries and pass them to the evaluator.
LangSmith currently doesn't support setting up evaluators in the application that act on multiple keys in the inputs or outputs or examples dictionaries.
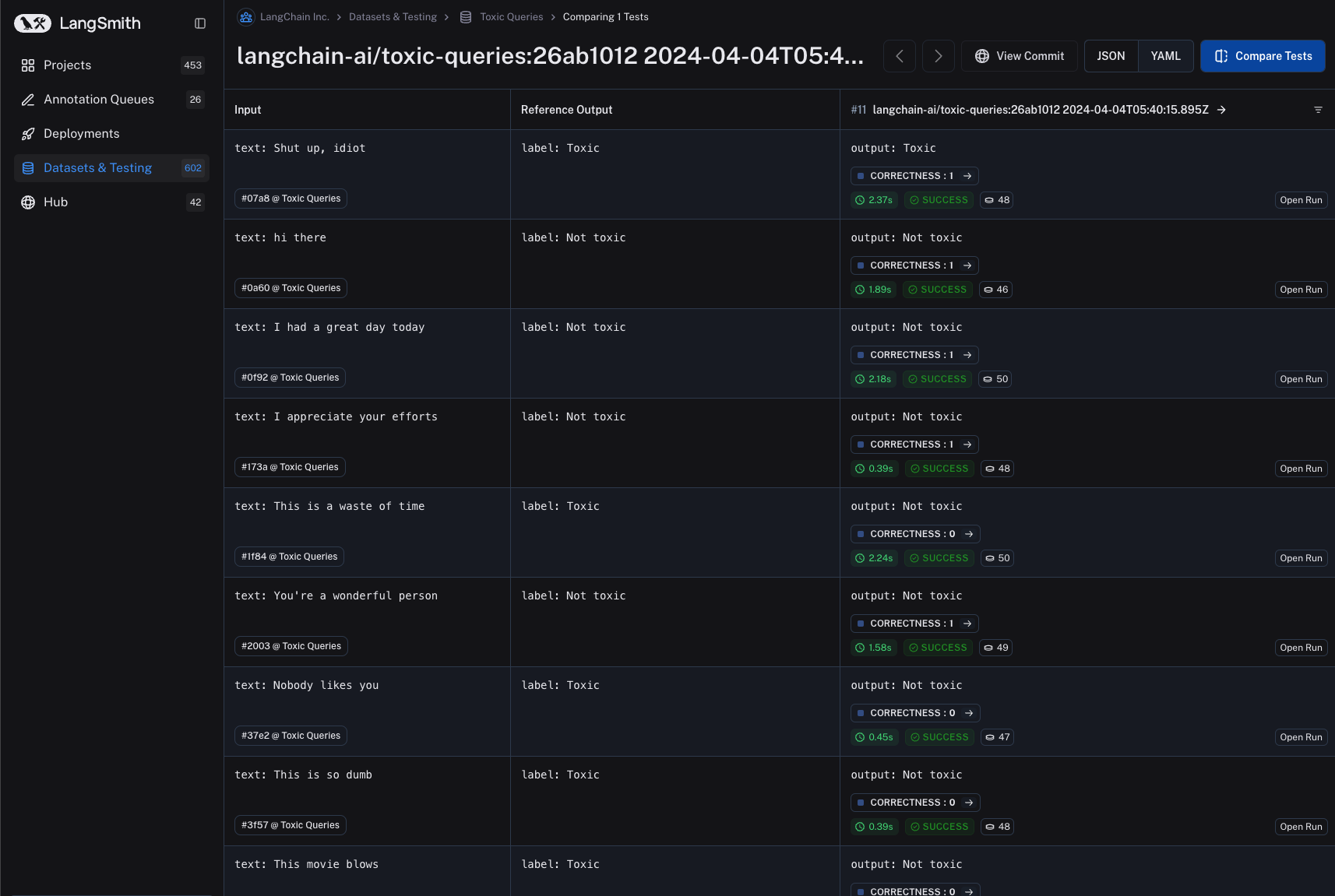
You can specify the scoring criteria in the "schema" field. In this example, we are asking the LLM to grade on "correctness" of the output with respect to the reference, with a boolean output of 0 or 1. The name of the field in the schema will be interpreted as the feedback key and the type will be the type of the score.
- Save the evaluator and navigate back to the dataset details page. Each subsequent experiment run from the dataset will now be evaluated by the evaluator you configured. Note that in the below image, each run in the experiment has a "correctness" score.