Prevent logging of sensitive data in traces
In some situations, you may need to prevent the inputs and outputs of your traces from being logged for privacy or security reasons. LangSmith provides a way to filter the inputs and outputs of your traces before they are sent to the LangSmith backend.
If you want to completely hide the inputs and outputs of your traces, you can set the following environment variables when running your application:
LANGCHAIN_HIDE_INPUTS=true
LANGCHAIN_HIDE_OUTPUTS=true
This works for both the LangSmith SDK (Python and TypeScript) and LangChain.
You can also customize and override this behavior for a given Client instance. This can be done by setting the hide_inputs and hide_outputs parameters on the Client object (hideInputs and hideOutputs in TypeScript).
For the example below, we will simply return an empty object for both hide_inputs and hide_outputs, but you can customize this to your needs.
- Python
- TypeScript
import openai
from langsmith import Client
from langsmith.wrappers import wrap_openai
openai_client = wrap_openai(openai.Client())
langsmith_client = Client(
hide_inputs=lambda inputs: {}, hide_outputs=lambda outputs: {}
)
# The trace produced will have its metadata present, but the inputs will be hidden
openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"},
],
langsmith_extra={"client": langsmith_client},
)
# The trace produced will not have hidden inputs and outputs
openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"},
],
)
import OpenAI from "openai";
import { Client } from "langsmith";
import { wrapOpenAI } from "langsmith/wrappers";
const langsmithClient = new Client({
hideInputs: (inputs) => ({}),
hideOutputs: (outputs) => ({}),
});
// The trace produced will have its metadata present, but the inputs will be hidden
const filteredOAIClient = wrapOpenAI(new OpenAI(), {
client: langsmithClient,
});
await filteredOAIClient.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hello!" },
],
});
const openaiClient = wrapOpenAI(new OpenAI());
// The trace produced will not have hidden inputs and outputs
await openaiClient.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hello!" },
],
});
Rule-based masking of inputs and outputs
This feature is available in the following LangSmith SDK versions:
- Python: 0.1.81 and above
- TypeScript: 0.1.33 and above
To mask specific data in inputs and outputs, you can use the create_anonymizer / createAnonymizer function and pass the newly created anonymizer when instantiating the client. The anonymizer can be either constructed from a list of regex patterns and the replacement values or from a function that accepts and returns a string value.
The anonymizer will be skipped for inputs if LANGCHAIN_HIDE_INPUTS = true. Same applies for outputs if LANGCHAIN_HIDE_OUTPUTS = true.
However, if inputs or outputs are to be sent to client, the anonymizer method will take precedence over functions found in hide_inputs and hide_outputs. By default, the create_anonymizer will only look at maximum of 10 nesting levels deep, which can be configured via the max_depth parameter.
- Python
- TypeScript
from langsmith.anonymizer import create_anonymizer
from langsmith import Client, traceable
# create anonymizer from list of regex patterns and replacement values
anonymizer = create_anonymizer([
{ "pattern": r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}", "replace": "<email>" },
{ "pattern": r"[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}", "replace": "<uuid>" }
])
# or create anonymizer from a function
anonymizer = create_anonymizer(lambda text: r"...".sub("[value]", text))
client = Client(anonymizer=anonymizer)
@traceable(client=client)
def main(inputs: dict) -> dict:
...
import { createAnonymizer } from "langsmith/anonymizer"
import { traceable } from "langsmith/traceable"
import { Client } from "langsmith"
// create anonymizer from list of regex patterns and replacement values
const anonymizer = createAnonymizer([
{ pattern: /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}/g, replace: "<email>" },
{ pattern: /[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}/g, replace: "<uuid>" }
])
// or create anonymizer from a function
const anonymizer = createAnonymizer((value) => value.replace("...", "<value>"))
const client = new Client({ anonymizer })
const main = traceable(async (inputs: any) => {
// ...
}, { client })
Please note, that using the anonymizer might incur a performance hit with complex regular expressions or large payloads, as the anonymizer serializes the payload to JSON before processing.
Improving the performance of anonymizer API is on our roadmap! If you are encountering performance issues, please contact us at support@langchain.dev.
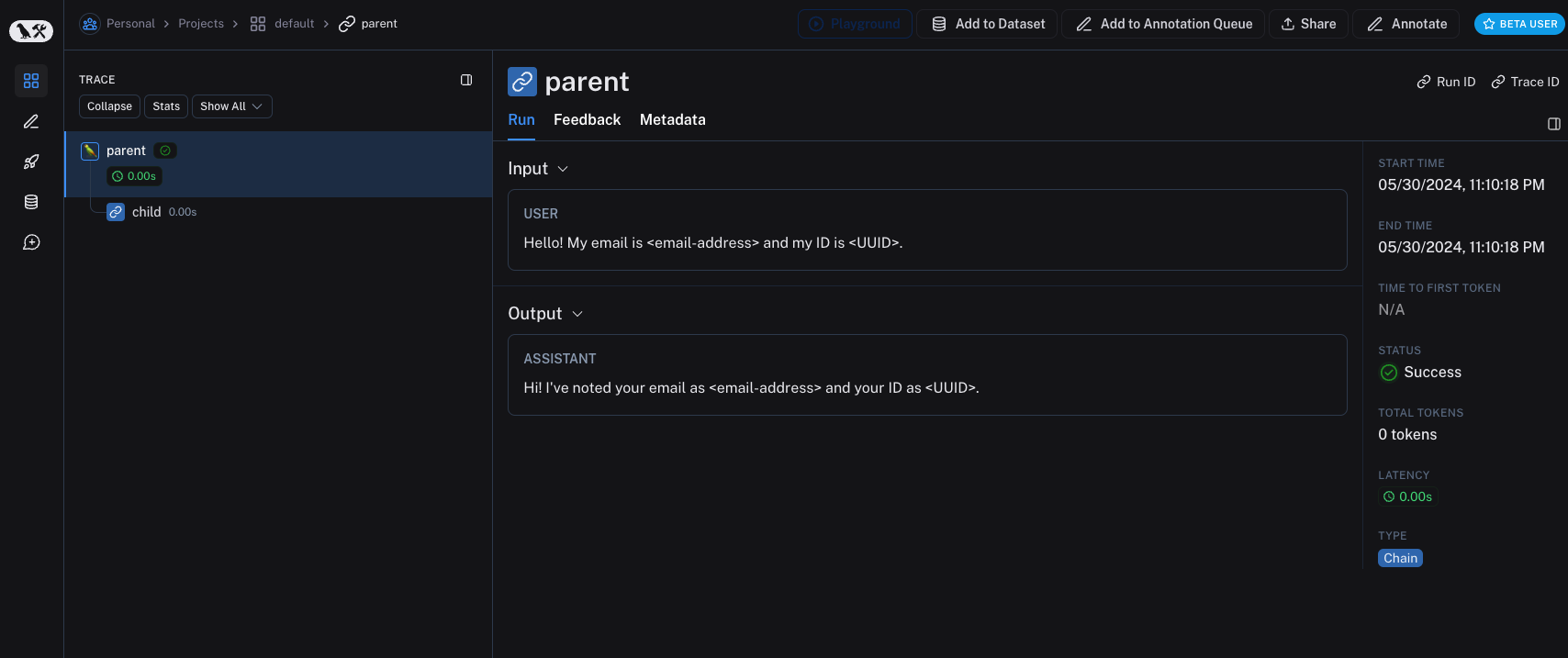
Older versions of LangSmith SDKs can use the hide_inputs and hide_outputs parameters to achieve the same effect. You can also use these parameters to process the inputs and outputs more efficiently as well.
- Python
- TypeScript
import re
from langsmith import Client, traceable
# Define the regex patterns for email addresses and UUIDs
EMAIL_REGEX = r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}"
UUID_REGEX = r"[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}"
def replace_sensitive_data(data, depth=10):
if depth == 0:
return data
if isinstance(data, dict):
return {k: replace_sensitive_data(v, depth-1) for k, v in data.items()}
elif isinstance(data, list):
return [replace_sensitive_data(item, depth-1) for item in data]
elif isinstance(data, str):
data = re.sub(EMAIL_REGEX, "<email-address>", data)
data = re.sub(UUID_REGEX, "<UUID>", data)
return data
else:
return data
client = Client(
hide_inputs=lambda inputs: replace_sensitive_data(inputs),
hide_outputs=lambda outputs: replace_sensitive_data(outputs)
)
inputs = {"role": "user", "content": "Hello! My email is user@example.com and my ID is 123e4567-e89b-12d3-a456-426614174000."}
outputs = {"role": "assistant", "content": "Hi! I've noted your email as user@example.com and your ID as 123e4567-e89b-12d3-a456-426614174000."}
@traceable(client=client)
def child(inputs: dict) -> dict:
return outputs
@traceable(client=client)
def parent(inputs: dict) -> dict:
child_outputs = child(inputs)
return child_outputs
parent(inputs)
import { Client } from "langsmith";
import { traceable } from "langsmith/traceable";
// Define the regex patterns for email addresses and UUIDs
const EMAIL_REGEX = /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}/g;
const UUID_REGEX = /[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}/g;
function replaceSensitiveData(data: any, depth: number = 10): any {
if (depth === 0) return data;
if (typeof data === "object" && !Array.isArray(data)) {
const result: Record<string, any> = {};
for (const [key, value] of Object.entries(data)) {
result[key] = replaceSensitiveData(value, depth - 1);
}
return result;
} else if (Array.isArray(data)) {
return data.map(item => replaceSensitiveData(item, depth - 1));
} else if (typeof data === "string") {
return data.replace(EMAIL_REGEX, "<email-address>").replace(UUID_REGEX, "<UUID>");
} else {
return data;
}
}
const langsmithClient = new Client({
hideInputs: (inputs) => replaceSensitiveData(inputs),
hideOutputs: (outputs) => replaceSensitiveData(outputs)
});
const inputs = {
role: "user",
content: "Hello! My email is user@example.com and my ID is 123e4567-e89b-12d3-a456-426614174000."
};
const outputs = {
role: "assistant",
content: "Hi! I've noted your email as <email-address> and your ID as <UUID>."
};
const child = traceable(async (inputs: any) => {
return outputs;
}, { name: "child", client: langsmithClient });
const parent = traceable(async (inputs: any) => {
const childOutputs = await child(inputs);
return childOutputs;
}, { name: "parent", client: langsmithClient });
await parent(inputs)
Processing Inputs & Outputs for a Single Function
The process_outputs parameter is available in LangSmith SDK version 0.1.98 and above for Python.
In addition to client-level input and output processing, LangSmith provides function-level processing through the process_inputs and process_outputs parameters of the @traceable decorator.
These parameters accept functions that allow you to transform the inputs and outputs of a specific function before they are logged to LangSmith. This is useful for reducing payload size, removing sensitive information, or customizing how an object should be serialized and represented in LangSmith for a particular function.
Here's an example of how to use process_inputs and process_outputs:
from langsmith import traceable
def process_inputs(inputs: dict) -> dict:
# inputs is a dictionary where keys are argument names and values are the provided arguments
# Return a new dictionary with processed inputs
return {
"processed_key": inputs.get("my_cool_key", "default"),
"length": len(inputs.get("my_cool_key", ""))
}
def process_outputs(output: Any) -> dict:
# output is the direct return value of the function
# Transform the output into a dictionary
# In this case, "output" will be an integer
return {"processed_output": str(output)}
@traceable(process_inputs=process_inputs, process_outputs=process_outputs)
def my_function(my_cool_key: str) -> int:
# Function implementation
return len(my_cool_key)
result = my_function("example")
In this example, process_inputs creates a new dictionary with processed input data, and process_outputs transforms the output into a specific format before logging to LangSmith.
It's recommended to avoid mutating the source objects in the processor functions. Instead, create and return new objects with the processed data.
For asynchronous functions, the usage is similar:
@traceable(process_inputs=process_inputs, process_outputs=process_outputs)
async def async_function(key: str) -> int:
# Async implementation
return len(key)
These function-level processors take precedence over client-level processors (hide_inputs and hide_outputs) when both are defined.